Мой МиниПК: https://shp.pub/78harg?erid=2SDnjcpjpv9
Видеокарта Geforse RTX4060 которую я использую для ИИ: https://alli.pub/799fvz?erid=2SDnjdPke6S
Давайте сначала рассмотрим, что такое Ollama.
Ollama — это проект с открытым исходным кодом, призванный стать мощной и удобной платформой для запуска программ LLM на локальном компьютере. Он совмещает сложность технологии LLM с потребностью в доступном и настраиваемом ИИ-интерфейсе.
По своей сути Ollama упрощает процесс загрузки, установки и взаимодействия с широким спектром LLM, позволяя пользователям исследовать их возможности без необходимости обладать обширными техническими знаниями или полагаться на облачные платформы.
Иными словами Ollama это инструмент который позволяет скачивать разные модули ИИ (LLM), такие как Deepseek, ChatGPT и запускать их.
Ollama может ставиться как на Windows, MacOS и на Linux. На сайте есть дистрибутивы установки: https://ollama.com/download
По сути с Ollama работать очень просто. Запустили программу, скачали модель – на сайте ollama их огромное количество: https://ollama.com/search и далее можно уже работать с моделью.
Так как моя любимая тема – это умный дом, то конечно хотелось бы использовать ИИ в умном доме. И Ollama позволяет такое делать с Home Assistant.
Но надо понимать, что для работы нейросетей нужны большие ресурсы. Если например использовать ИИ на вычислительной мощности процессора, то результат будет скверный.
И для домашней реализации немного ситуацию выправляет видеокарта. Причем у видеокарты важна именно её память. Например у меня видеокарта Nvidia RTX 4060 https://alli.pub/799fvz?erid=2SDnjdPke6S которая имеет 8 гб памяти. И если у Вас модель LLM весит до 8гб – то она загружается вся в память видеокарты и работает на всей вычислительной мощности видеокарты – ну будем считать это хорошим результатом.
А вот если модель например 12гб, то она не помещается в 8гб памяти видеокарты. Тем самым она еще будет обрабатываться на процессоре – что заметно ухудшит время ответа LLM нам на вопрос. По этому чем больше памяти у видеокарты, тем лучше.
Установка Ollama в Home Assistant:
Ollama может дружить с Home Assistant как установленная отдельно например на отдельном linux сервере (эту установку я покажу в следующей статье). А можно установить прям как addon в Home Assistant.
Такой экземпляр ollama вполне рабочий, полноценный, он постоянно обновляется. Но есть конечно и минусы такой установки.
Главный минус это вес. Дело в том, что модели ИИ весят довольно много и когда такая модель установлена – то Home Assisatnt (если у Вас настроены резервные копии) создает резервную копию в том числе и этой модели, тем самым копия сильно увеличивается в размерах. У меня резервные копии копируются на google drive где всего 15гб свободного места и такие бэкапы мне сразу забьют место.
Ну а второй минус, это сложная настройка в плане работы на видеокарте. Если видеокарты нет и планируете работу только на процессоре, то данный вариант самое то для Вас.
Устанавливается все просто, нужно в Магазин дополнений Home Assisant добавить в “репозитории дополнений” новый репозиторий: https://github.com/SirUli/homeassistant-ollama-addon
После добавления репозитория нужно либо перезапустить Home Assistant, либо проверить наличие обновления. И у Вас появится addon для установки:
Устанавливаем его.
После установки можно перейти в Конфигурацию аддона и посмотреть или поменять параметры:
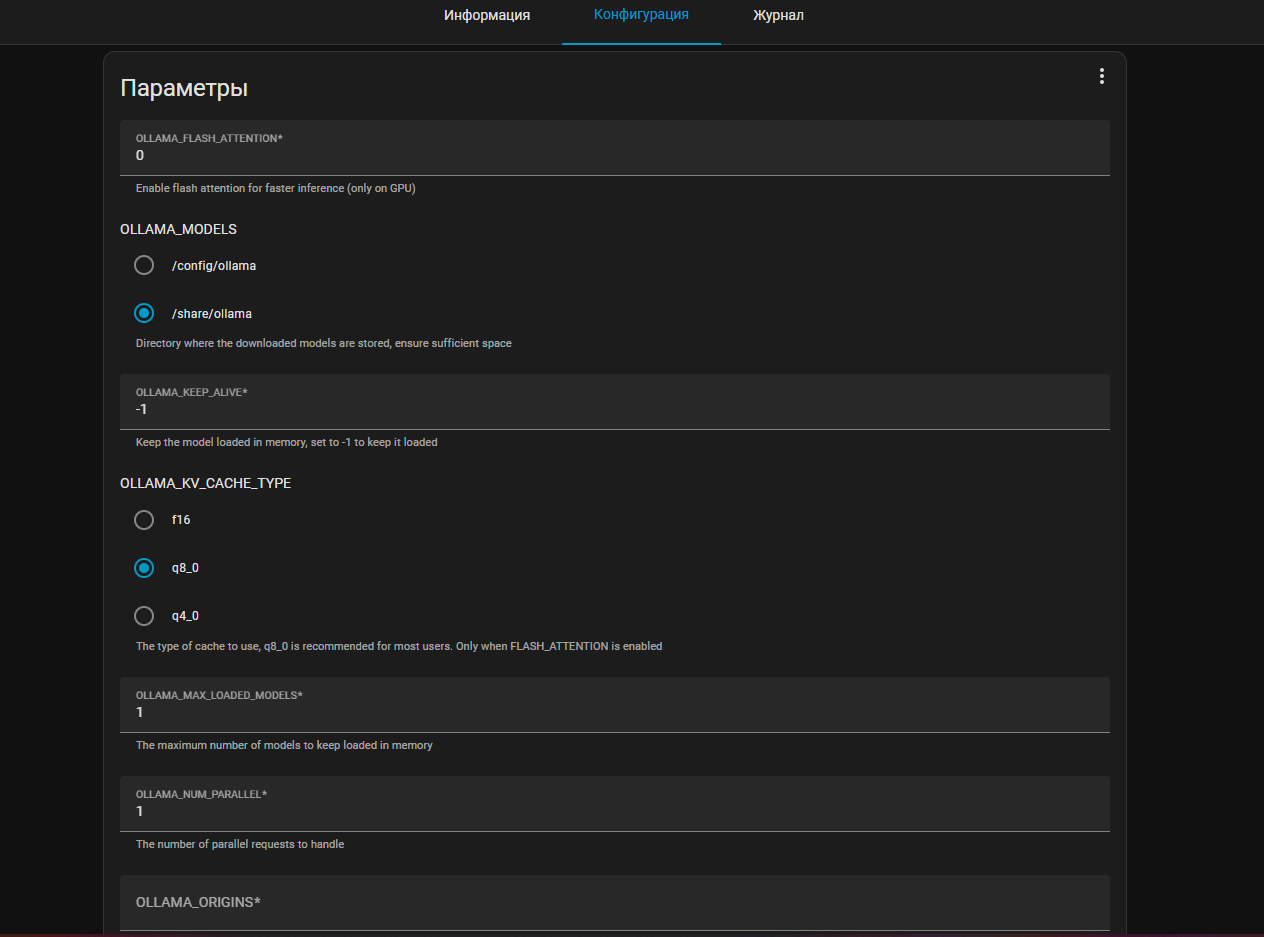
Параметров тут не много и на мой взгляд самое полезное тут – это выбор того, куда будут сохраняться LLM модели, чтоб понимать откуда их удалять. Так как весят они не мало.
При таком выборе /share/ollama модели будут храниться собственно в /share/ollama:
Ну собственно запускаем аддон и после запуска по сути ничего не должно произойти.
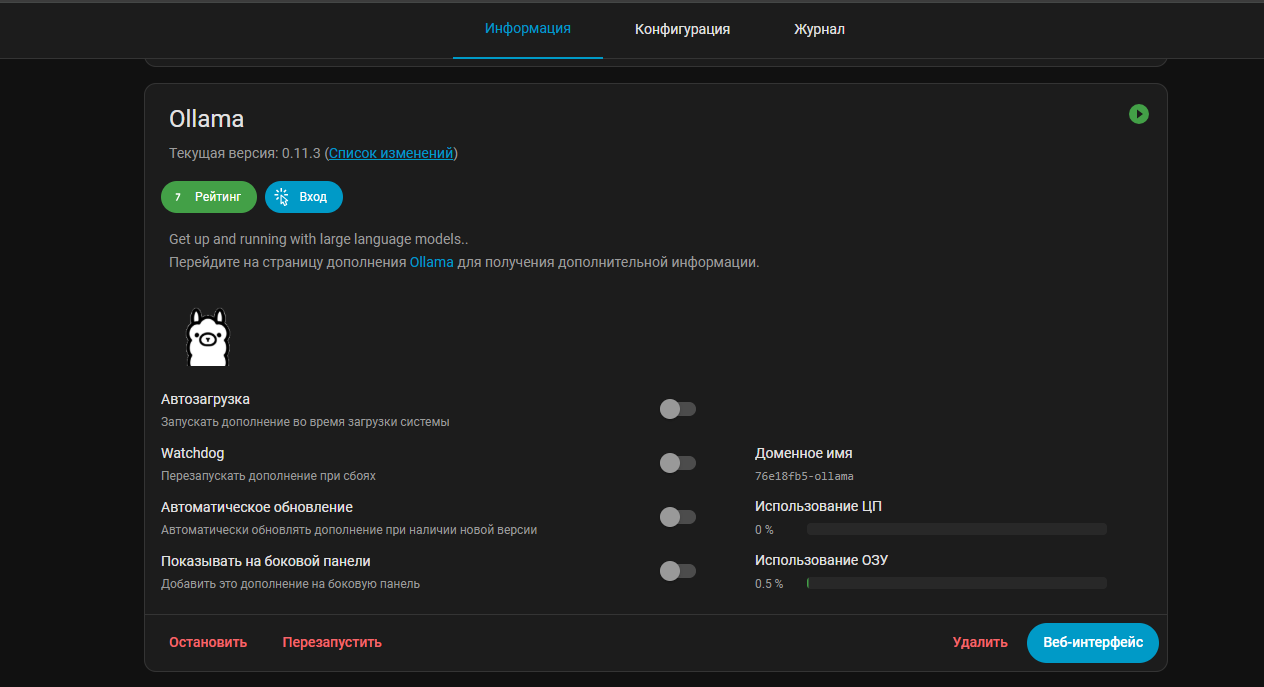
Но нам нужно зайти в Веб интерфейс и посмотреть какая там ссылка:
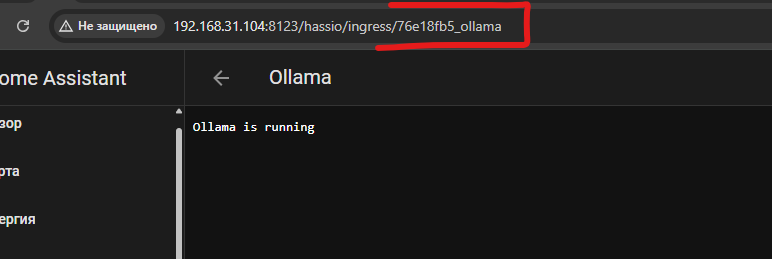
У меня получается адрес ollama будет http://76e18fb5_ollama:11434 – порт стандартный и он указывается в конфигурации аддона. Запоминаем эту ссылку, она нам дальше понадобится.
все управление ollama уже будет происходить через интеграцию Ollama, которая встроена в Home Assistant и нам достаточно только зайти в Настройки -> интеграции и там её найти и установить.
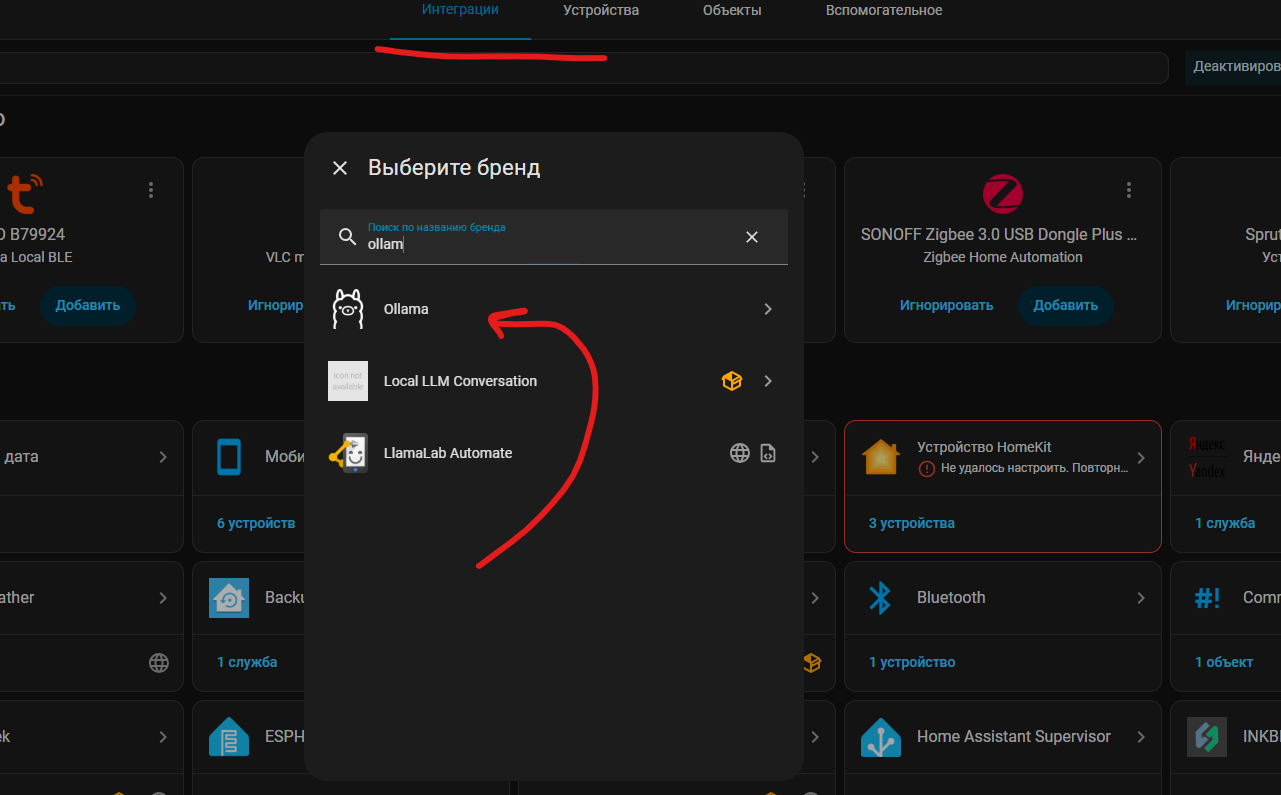
Далее у нас попросит ввести url адрес для того, чтоб интеграция понимала к какому серверу подключаться
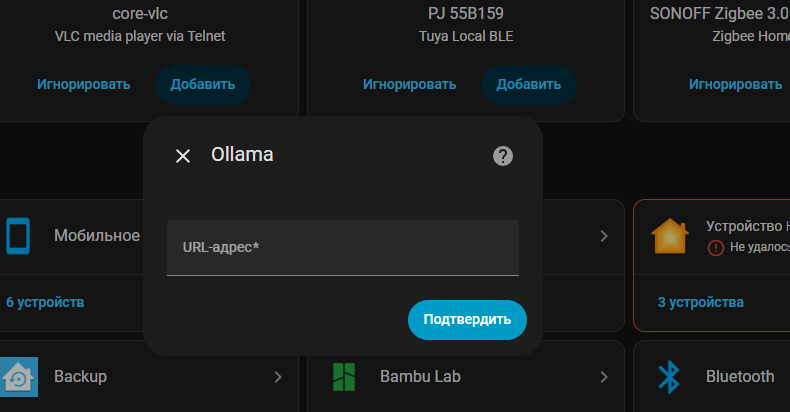
URL нужно указать который я описывал выше, у меня это: http://76e18fb5_ollama:11434
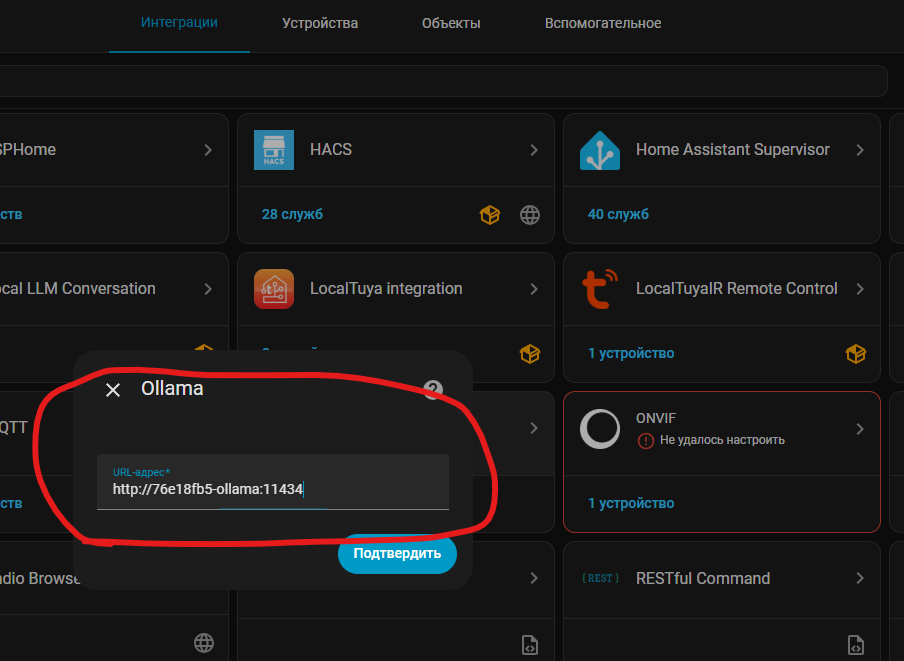
После этого настроим интеграцию:
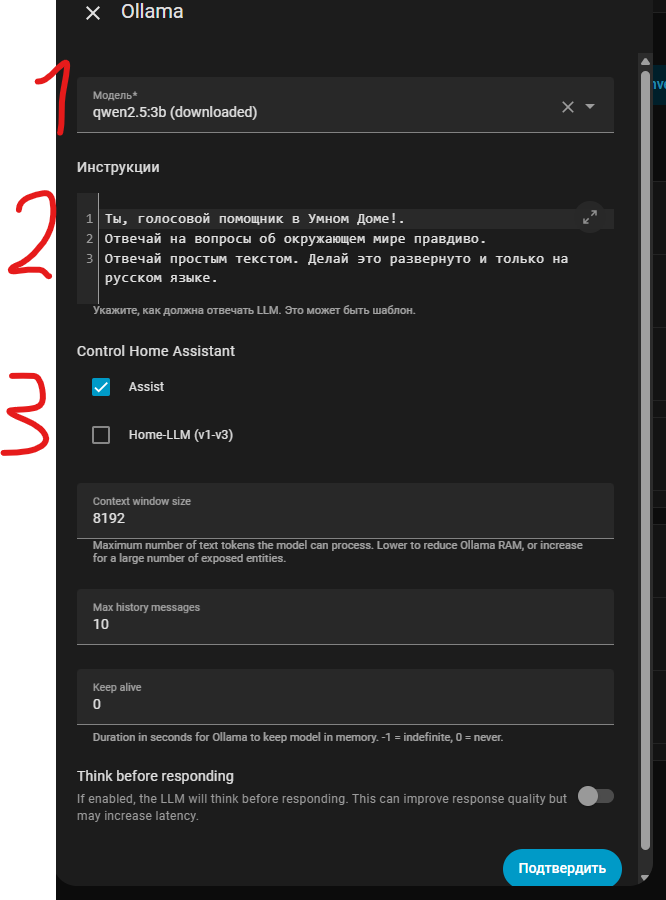
- Это модель – тут выбираем её из списка и после её выбора и подтверждения она скачается в Addon ollama. Моделей можно сколько угодно поставить для тестов, но учтите, они много весят.
- Инструкции – это роль от которой будет отталкиваться модель. Ну например у меня это Голосовой помощник умного дома. Но вы можете например ему прописать роль домового или еще чего-то. По сути особо это ни на что не влияет, только на ответы от имени кого.
- Тут выбирается чем будет управлять ваша LLM. Если выбрано Assist, то она собственно управляет умным домом Home Assistant
Так как в Home Assisant Ассистент главный так и называется Assist:
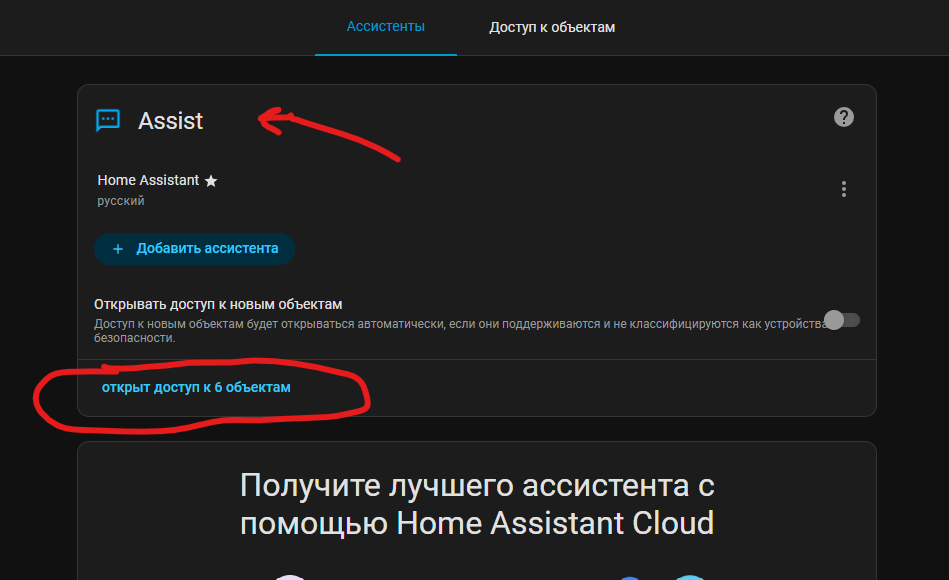
Тут же в Assist выдаёте доступ к объектам умного дома. Например у меня как можете увидеть 6 объектов. Это важно. Дело в том, что пока LLM не умеет работать со всем умным домом Home Assisant. Например у меня было 400 объектов и мои команды ИИ не выполнял. Тупил сильно, путался.
И я прочел что оказывается, рекомендуется примерно 20-30 объектов только отдавать ИИ не больше. И когда я уменьшил количество объектов все стало хорошо работать.
Ну и в настройках еще Ассистента нужно выбрать Ollama для работы:
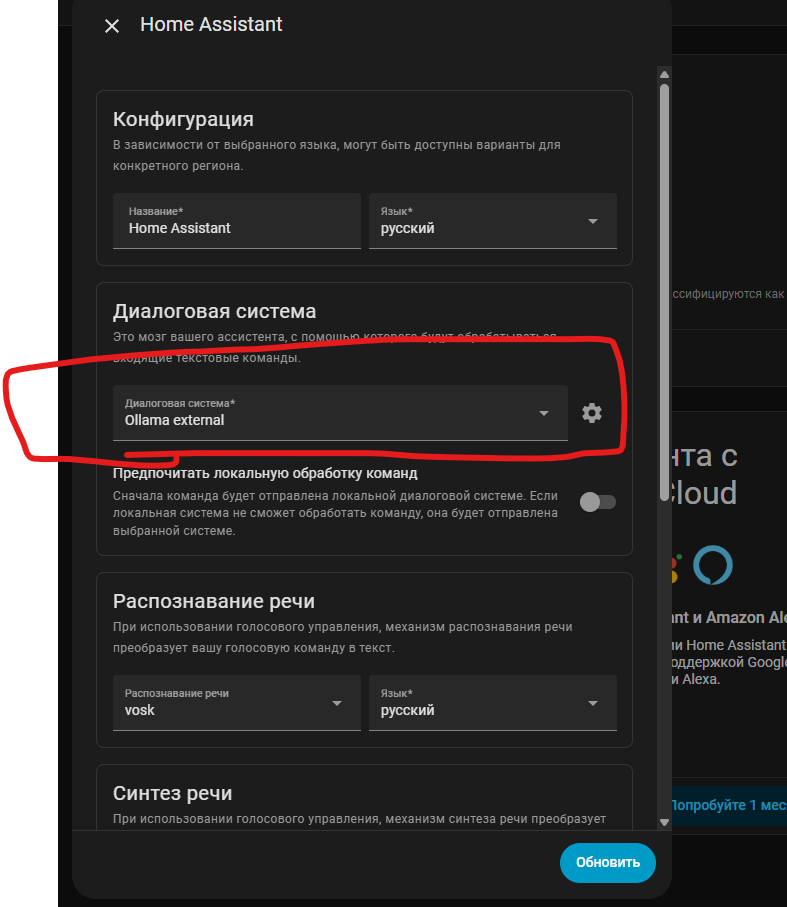
Ну и как результат работает это следующим образом:
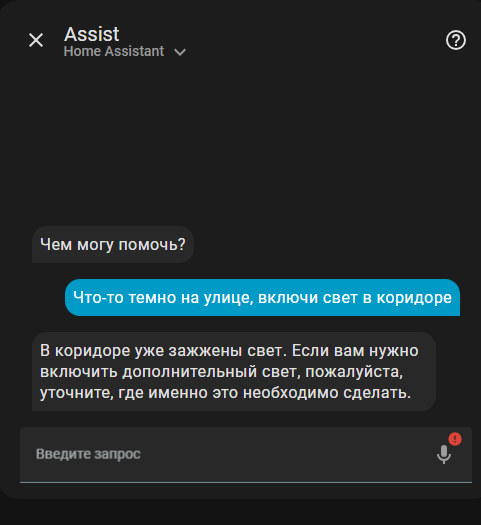
Не обязательно давать четкие команды, ИИ и так понимает, что ему нужно сделать.