
Сервер на котором я провожу испытания: https://alli.pub/79xbq6?erid=2SDnjeV6fzW
Моя видеокарта: https://alli.pub/79xbqd?erid=2SDnjefUaxv
Дешевая видеокарта для опытов: https://alli.pub/79xbqr?erid=2SDnjepNWez
В этой статье рассмотрим как установить LLC Ollama на операционную систему Linux, например Ubuntu. И покажу как с ней работать.
Это будет полезно используя ИИ например в связке управления умным домом Home Assistant, или написании кода – так как существуют для Ollama специальные языковые модели, которые по вашему запросу будут писать Вам программный код. Ну так-же Ollama можно “прикрутить” к frigate и тогда с помощью нейросетей будет распознавание объектов с описанием этого объекта искусственным интеллектом.
Я Ollama начал изучать именно для того, чтоб прикрутить его к Home Assistant. Но оказалось – применения очень много всякого.
У Ollama есть сайт с кучей моделей ИИ: https://ollama.com/search
Там очень много разных моделей. И Deepseek r1 и qween, gemma и прочее прочее. на любой вкус можно найти.
В дальнейшем в статье я покажу как их устанавливать.
Конечно-же Использование искусственного интеллекта требует огромных ресурсов, на то, чтоб он быстро вам формировал ответы. В домашних условиях это сделать довольно сложно. Но Ollama может работать на вычислительных мощностях видеокарт – на которой она существенно быстрее начинает работать. Если сравнивать работу на CPU и GPU, то видеокарта просто кратно лучше работает.
По этому будем рассматривать вариант работы Ollama именно на видеокарте – хотя и на CPU тоже будет работать – но придётся подольше подождать ответа.
Так-же нужно иметь ввиду, что вся языковая модель при использовании GPU (видеокарты) хранится в оперативной памяти самой видеокарты. И получается чем больше памяти в видеокарте, тем большая модель поместится в неё.
Для примера у меня видеокарта GeForce RTX4060 с 8гб памяти и я могу запускать модели на ней весом до 8 гб. Если модель весит больше, то она уже будет использовать CPU и существенно медленнее работать.
Установку Ollama будем рассматривать в proxmox и на виртуальную машину с Ubuntu. Для использования Ollama с видеокартой в proxmox, нужно предварительные манипуляции сначала провести с самим proxmox, в потом и виртуальной машине.
Подготовка Proxmox для работы с видеокартой:
Для начала нам нужно отвязать видеокарту, чтоб её ОС proxmox просто так не использовала и тогда нам дастся возможность видеокарту прокинуть до виртуальной машины.
Данной командой мы увидим, как определилась видеокарта и её uid.
lspci -nn | grep -i nvidia
Вывод будет примерно такой:

Тут нужно обратить внимание, что определилось 2 устройство. VGA видеокарта RTX4060 с ids [10de:2882] и аудио девайс с ids [10de:22be].
Вот эти ids нужно запомнить и дальше их добавить в конфиг.
Добавляем эти ids в файл vfio-pci:
nano /etc/modprobe.d/vfio.conf
И такую строчку добавляем:
options vfio-pci ids=10de:2882,10de:22be disable_vga=1
где ids это те которые мы выяснили выше и записали их через запятую.
Далее нам нужно добавить драйверы NVIDIA в черный список, чтоб запретить Proxmox использовать их:
Для этого вводим серию команд:
cat <<EOF > /etc/modprobe.d/blacklist-nvidia.conf
blacklist nouveau
blacklist nvidia
blacklist nvidiafb
blacklist rivafb
EOF
Теперь нам нужно добавить модули vfio в /etc/modules:
echo -e "vfio\nvfio_iommu_type1\nvfio_pci\nvfio_virqfd" >> /etc/modules
update-initramfs -u -k all
reboot
После перезагрузки можно проверить командами используется ли proxmox видеокарта или нет. Эти команды не должны ничего выдать. ids там ваш должен быть.
lspci -nnk | grep -iA 3 '10de:1c03'
lspci -nnk | grep -iA 3 '10de:10f1'
Проброс видеокарты в виртуальную машину на Proxmox:
После проделанных манипуляций отвязки видеокарты от proxmox мы её прокинем в виртуальную машину. Ну и будем считать, что Linux например ubuntu вы уже сами установили в proxmox и туда мы и будем прокидывать видеокарту.
Нам опять понадобится команда:
lspci -nn | grep -i nvidia
Которая вывела видеокарту – как она определилась в системе и показала её ids:
Но тут еще есть uid как они определились в системе. У меня 2 uid’а:
05:00.0 и 05:00.1 – эти 2 устройства и прокинем в виртуалку.
В Web интерфейсе Proxmox клацаем по виртуальной машине, Выбираем “Hardware” -> нажимаем кнопка add-> PCI Device
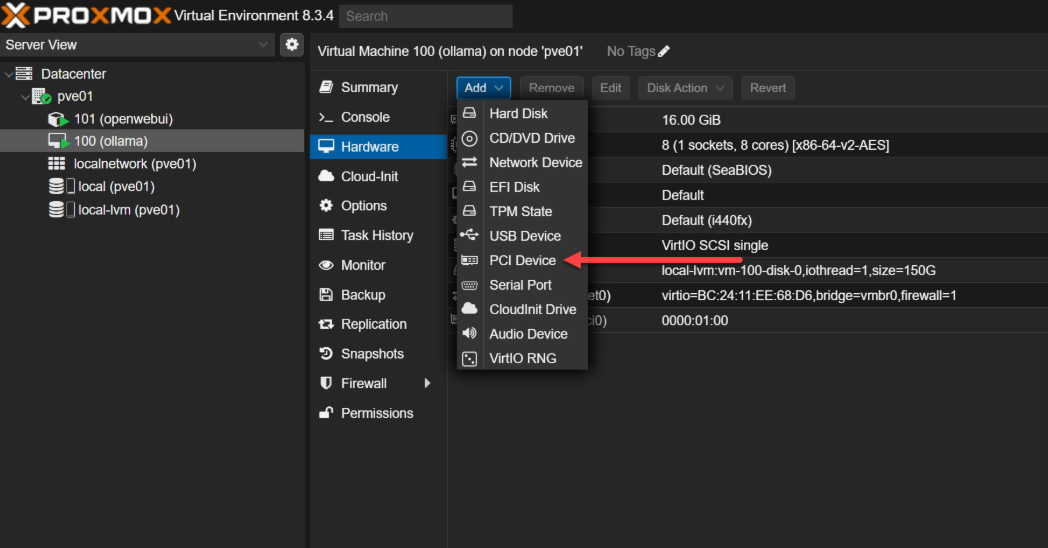
Далее переводим галочку в Raw Device, убираем галочку с Primary GPU и выбираем наши два девайся 05:00.0 и 05:00.1. Естественно по очереди.
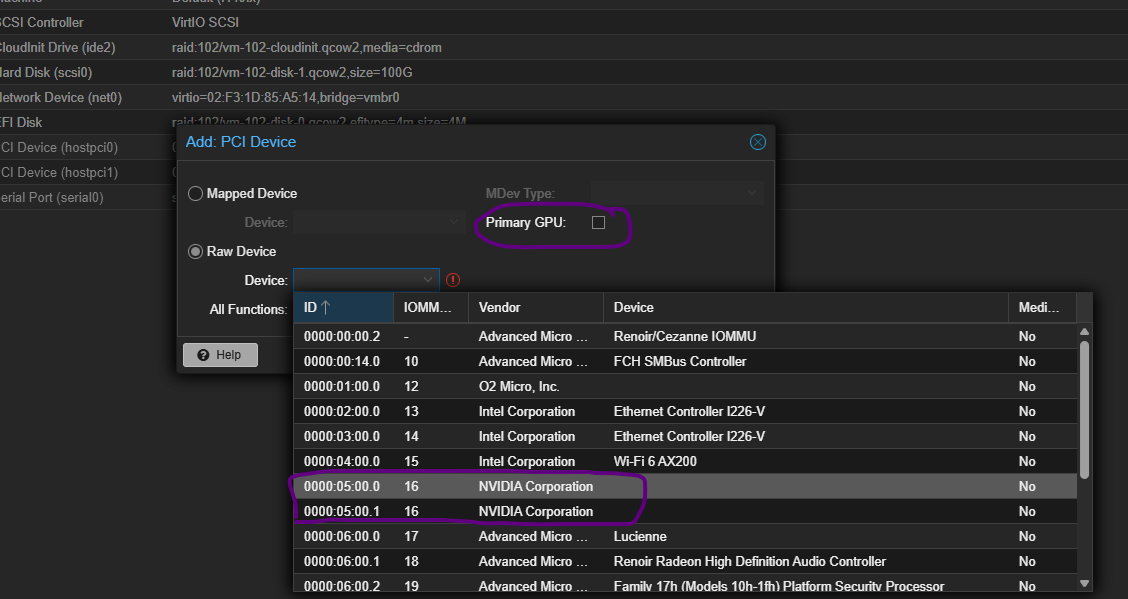
Должно получиться так:
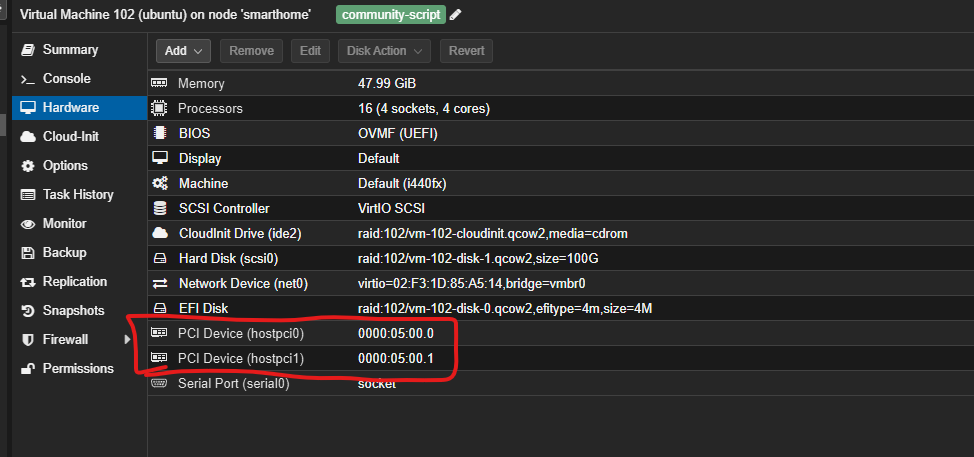
Готово, теперь перезапускаем виртуальную машину и можем уже в ней переходить к установке Ollama.
Установка Ollama:
В виртуальной машине на которую мы будем устанавливать Ollama, нужно установить драйвера для видеокарты.
sudo apt update
sudo apt install -y nvidia-driver-570
sudo reboot
После установки дров можно проверить их работу, для этого нужно ввести команду:
nvidia-smi
И вывести должно что-то типо такого:
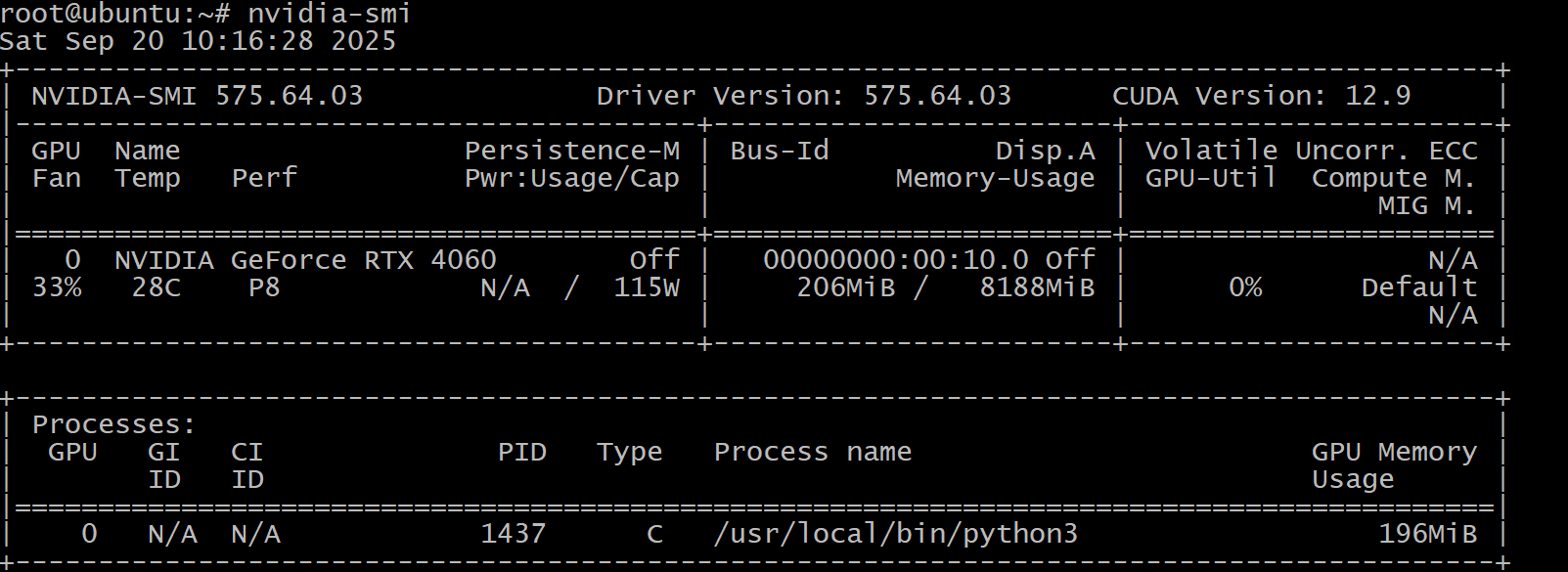
Это говорит о том, что драйвер установился правильно, он определил модель видеокарты прокинутой в виртуалку. ПОказывает её температуру, загрузку, потребление.
Ну и теперь можем приступить к установке ollama. А установка тут всего одной командой. Нужно запустить скрипт, который сам все сделает.
По итогу устанавливаем ollama командой:
curl -fsSL https://ollama.com/install.sh | sh
После установки Ollama, по умолчанию она не разрешает к ней подключаться по сети. Ну например тот же home assistant не подключить, или удобный клиент для задавания вопросов ИИ не получится использовать. Потому что все это дело работает по порту 11434, который по умолчанию закрыт.
Вот давайте его и откроем.
ЧТоб открыть API Ollama нужно выполнить команду:
nano /etc/systemd/system/ollama.service
Далее туда вставить следующее:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
Сохраняем файл “cntr+x” “Y“.
И перезапускаем службы
sudo systemctl daemon-reload
sudo systemctl restart ollama
Ну и проверить работу можно командой:
ss -tulnp | grep 11434

Работа с Ollama из командной строки:
Теперь после установки, давайте я познакомлю Вас с базовыми командами, чтоб вы могли сразу работать в консоли.
Первая команда, это команда запуска ollama с определенной моделью. Вы находите модель на официальном сайте Ollama: https://ollama.com/search
И чтоб её скачать и запустить достаточно ввести команду:
ollama run qwen3
Команда сразу скачает модель qwen3 и запустит её. Если модель скачена, то запустит сразу, если нет, то качать еще будет несколько минут, в зависимости от её веса.
Ну и после запуска в send a massage можно вписать вопрос, и вам нейросеть ответит:
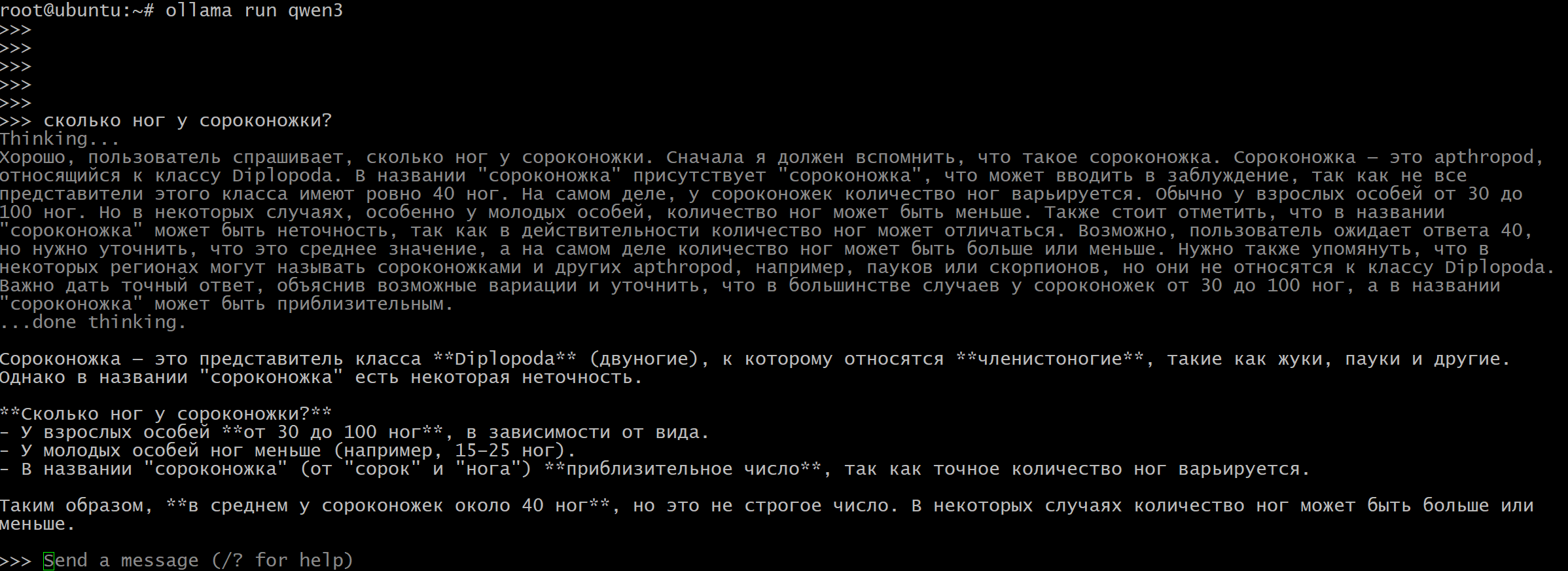
Так-же можно проверить на чем модель у нас сейчас работает, на процессоре или видеокарте. Для этого нужно вбить команду:
ollama ps

Тут видно, что модель занимает 6.5Gb – на мою видеокарту она влезла и по этому на 100% используется видеокарта.
Чтоб остановить модель достаточно вбить команду
ollama stop qwen3:latest
Еще интересная команда, которая показывает очки, сколько набрал тот или иной запрос. С помощью этой команды можно проверять на какой видеокарте лучше работают запросы и сравнить с процессором. Команда:
ollama run qwen3 --verbose
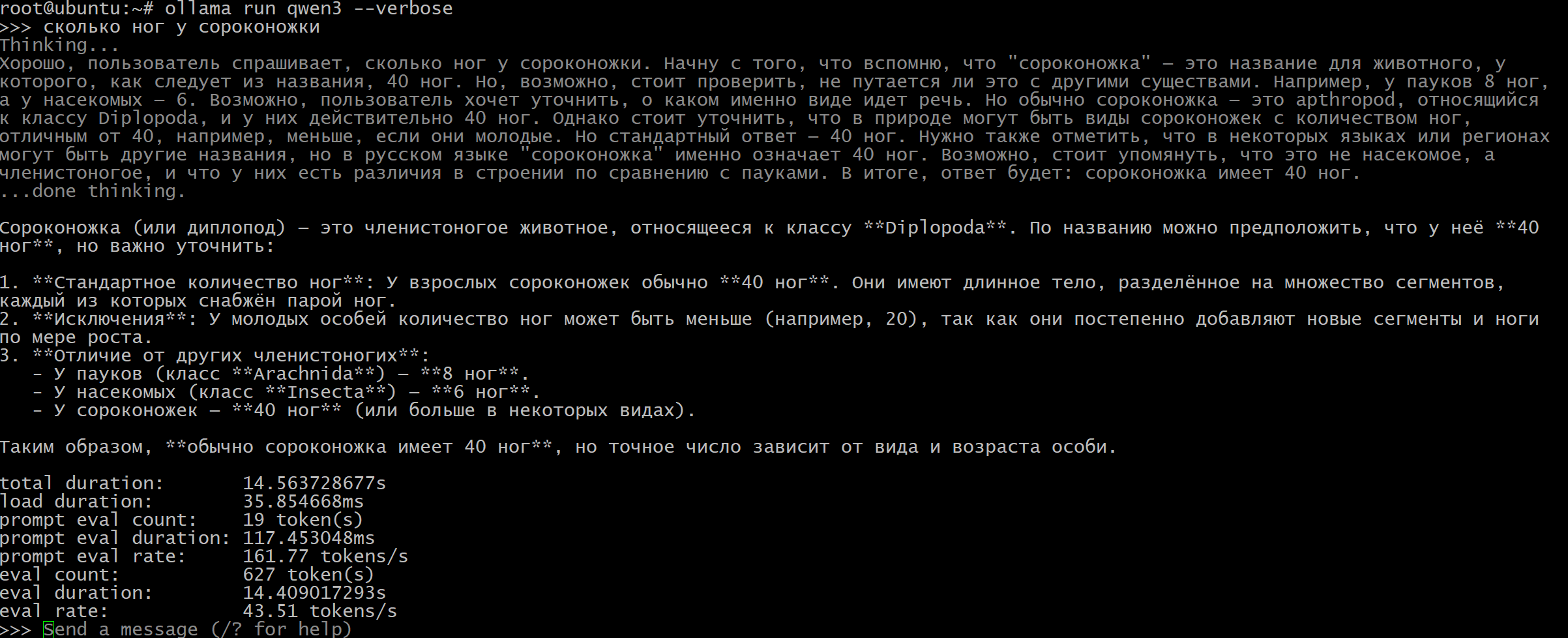
по сути достаточно обращать внимание на total duration – это за сколько секунд запрос выполнился. у меня это 14.5 секунд и eval rate – это сколько токенов в секунду вычислительная мощность. у меня это 43.5 токена в секунду.
А вот давайте посмотрим другой вариант. Я сейчас запущу модель qwen3, которая весит больше 8гб и она у меня не влезет в видеокарту. По этому исполняется на процессоре+ видеокарта.
Вот так это выглядит:

Тут видно, что 21% использует CPU и 79% на видеокарте. Но это очень плохо. Разница в разы хуже.
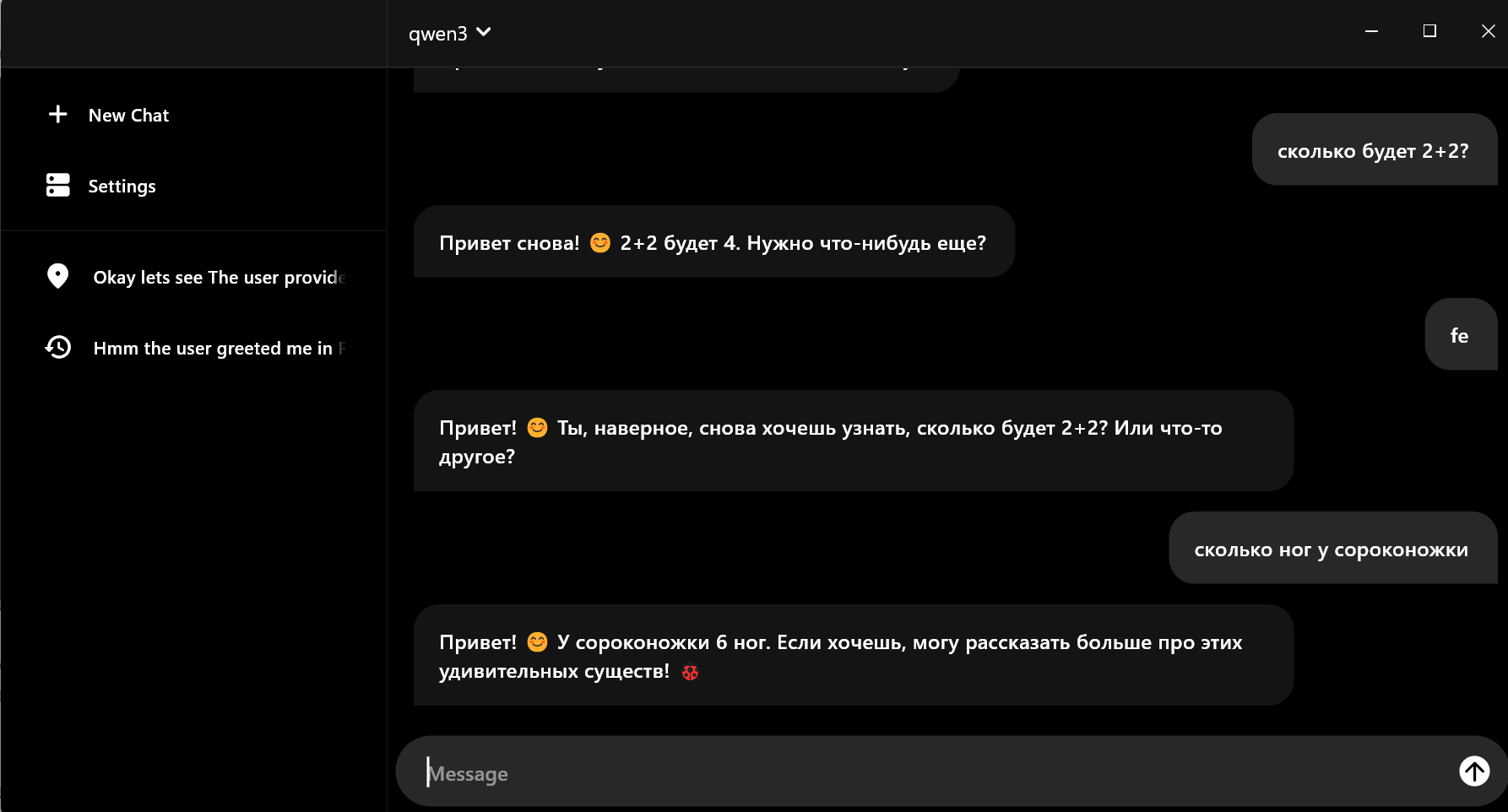
Выполнил тот же запрос “сколько ног у сороконожки” с ключем –verbose и вот он результат:
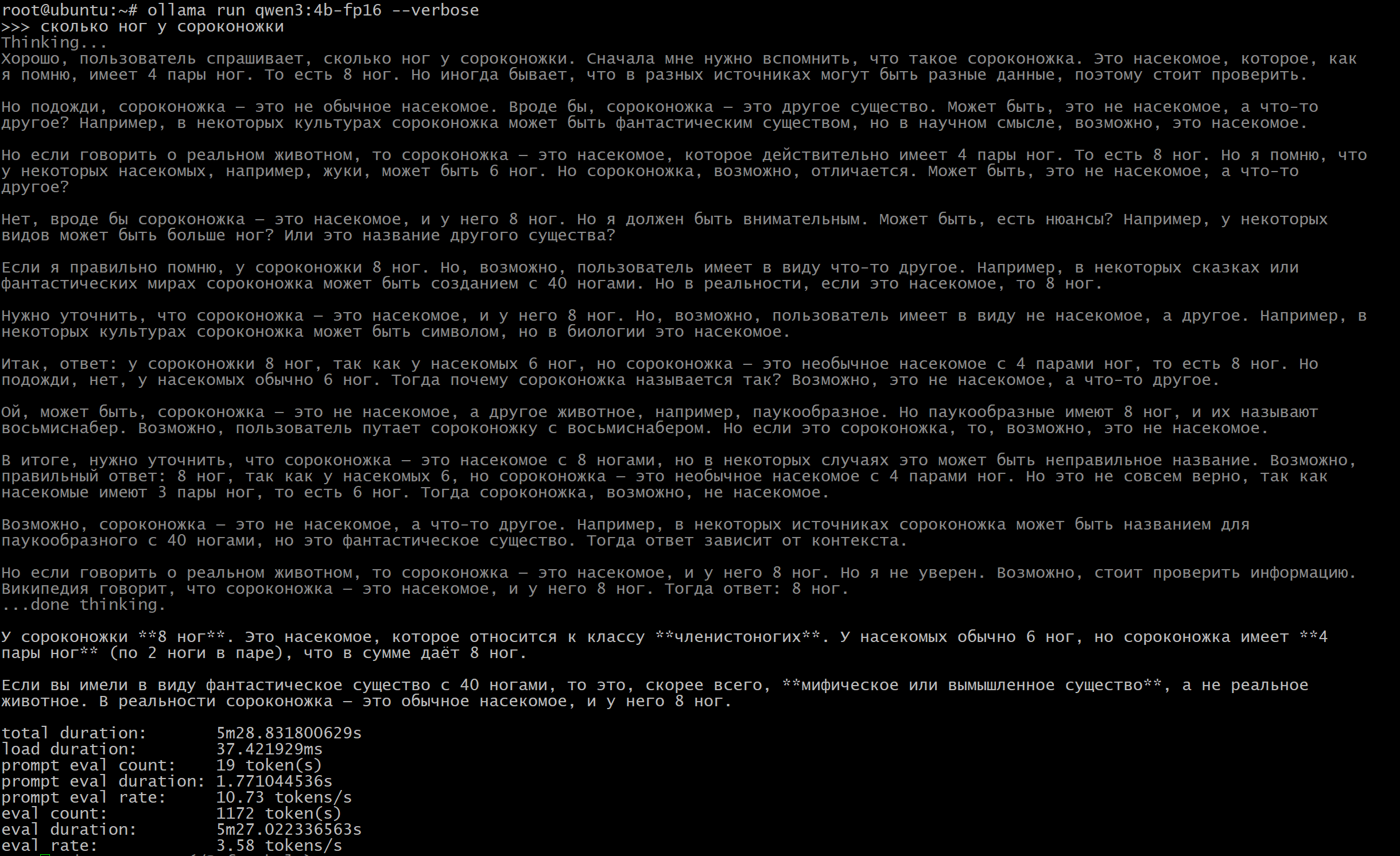
если на видеокарте это исполнялось 14.5 секунд, то вот на процессор плюс видео уже 5 минут 28 секунд. и 3.58 токена в секунду, а на видюхе 45 токенов. Вот вам и разница.
И тут неважно сколько у Вас оперативной памяти на компьютере – ollama её вообще не использует, по этому много её тут не надо. Важна память видеокарты и мощность видеокарты.
Что-то я увлёкся. Давайте еще пару команд базовых покажу.
ollama list
Покажет сколько у вас установлено разных моделей:
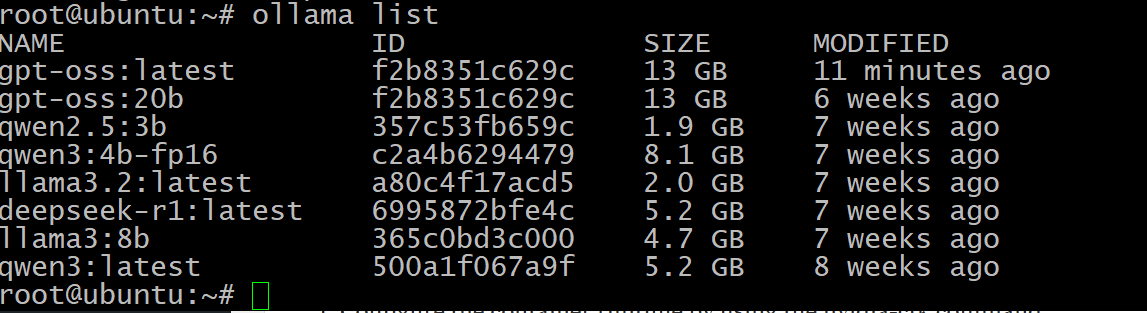
Как видим, у меня их довольно много и весят они много. Есть даже одинаковые, которые надо бы удалить. И вот последняя команда базовая, которая позволит удалить модели:
ollama rm gpt-oss
где gpt-oss имя модели.
Обновление Ollama:
Чтоб обновить ollama, достаточно её остановить и еще раз запустить скрипт установки, который сам все обновит:
systemctl stop ollama
и
curl -fsSL https://ollama.com/install.sh | sh
Установка Open-webui:
Есть такой еще web интерфейс для работы с ollama, под названием open-webui. Через него можно взаимодействовать с моделями, но устанавливается он довольно сложно.
Установка toolbox nvidia:
Сначала добавить репозитории:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey |sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list && sudo apt-get updatesudo apt-get install -y nvidia-container-toolkitsudo nvidia-ctk runtime configure --runtime=dockerПерезапускаем демон:
sudo systemctl restart dockernvidia-smish <(curl -sSL https://get.docker.com)docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
Ollama app:
Работа Ollama в Home Assistant:
В Home Assistant все настраивается так-же как и в этой статье я описывал:
просто в интеграции ollama в home assitsant нужно указать ip адрес сервера ollama и порт:
Ну а остальное все настраивается как в той статье которую я приложил чуть выше.
Вывод:
В этой статье я постарался все описать, что знаю на данный момент про ollama. Тема очень интересная, мне надо еще видео о ней снять и постепенно использовать её в разных сервисах. Сначала покажу в видео как в Home Assistant он работает, а потом думаю и к frigate подойдём, там посмотрим.
Реклама: ООО “АЛИБАБА.КОМ (РУ)” ИНН: 7703380158
Реклама: ООО “Яндекс Маркет” ИНН: 9704254424